
Automated recommendations have become a pervasive feature of our online user experience, and due to their practical importance, recommender systems also represent an active area of scientific research. Historically, the two main approaches of building recommender systems are collaborative filtering (CF) and content-based filtering (CBF). In its pure form, collaborative filtering relies on the identification of preference patterns in a user community. Content-based filtering approaches, in contrast, only consider the past preferences of an individual user and try to learn a preference model based on a feature-based representation of the content of recommendable items.
Due to the potential limitations of considering only the past preferences of an individual user, a number of proposals were made over the past two decades to combine both algorithmic approaches in hybrid methods. In more recent years, we furthermore observe various attempts to incorporate additional side information and external knowledge sources into the recommendation process. In the case of content-based methods, this side information predominantly contains additional knowledge about the recommendable items, e.g., in terms of their features, metadata, category assignments, relations to other items, user-provided tags and comments, or related textual or multimedia content.
While pure collaborative filtering methods dominate the research landscape (Jannach et al. 2012), considering information about the “content” (i.e., the features of the items) is highly important in many of today’s practical applications of recommenders, and will be increasingly relevant in the future for a number of reasons:
This special issue contains a selection of recent work on building recommender systems using rich item descriptions. We outline these papers in Sect. 3. Before that, in Sect. 2, we briefly reflect on the history of the field, discuss recent trends, and sketch potential future developments.
Some of the underlying ideas of content-based filtering go back to the 1960s and to early ideas of what was called “Selective Dissemination of Information” (Hensley 1963). Here, the goal was to distribute information based on matching newly arriving information items with the assumed interests of the recipients that are stored in user profiles. Another root of CB-filtering systems lies in the field of Information Retrieval (IR). Content-based approaches for example often rely on document encodings that were developed in this field (Salton and McGill 1986). In the Web era, content-based techniques were later successfully applied in different domains, e.g., to make personalized recommendations of interesting web pages (Pazzani et al. 1996).
Soon, however, it turned out that pure content-based filtering approaches can have several limitations in many application scenarios, in particular when compared to collaborative filtering systems. One main problem is that CBF systems mostly do not consider the quality of the items in the recommendation process. For example, a content-based recommendation in the movie domain might result in an obscure, low-quality movie similar to those the user liked in the past. CF methods usually take such information into account, either by considering explicit item ratings or by indirectly factoring in item popularity in implicit feedback scenarios.
With a decades-long focus of academic research on finding the best model in terms of prediction accuracy, pure CBF methods almost seemed obsolete and they were instead mostly used to boost the performance of collaborative filtering approaches, e.g., in cold-start situations (Melville et al. 2002). However, along with the availability of new knowledge sources—including both structured and unstructured ones, such as user-generated content—comes a steady stream of new proposals for hybrid systems that leverage such information to make better predictions. Furthermore, in some new application scenarios, it is actually important that the recommended items are actually content-wise similar to a reference item, e.g., for similar item recommendation (Yao and Harper 2018). Also, in an automated music radio station, content features can be used to ensure that the radio does not drift away too much from the seed tracks. Finally, content information also enables the generation of better explanations (Gedikli et al. 2014), which is becoming increasingly important in the context of fair and transparent recommender systems.
In the last decade, we could therefore observe a number of works that either use new types of side information (e.g., metadata or user-generated content) for recommendation or propose new algorithmic approaches to process the available information. Figure 1 shows an overview of these new trends.
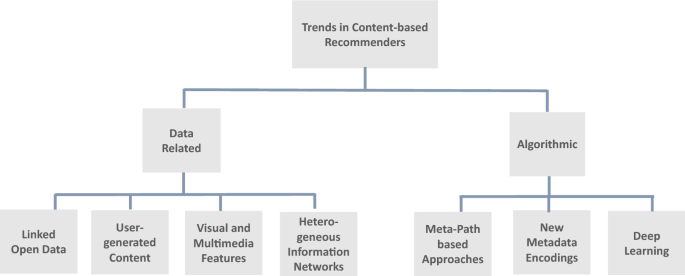
Linked open data Traditionally, content-based recommender systems used metadata descriptions of items, or full-text indexing of textual items (Belkin and Croft 1992). Today, the introduction of Linked Open Data (LOD) offers new ways to extend item descriptions with external knowledge sources (Di Noia et al. 2012; Musto et al. 2017b). Early work by Passant (2010), for example, used DBpedia as an external knowledge source for music recommendation. Since then, Linked Open Data was used to enrich item descriptions for many application domains, including movie and book recommendation (Musto et al. 2017a), and music and sound recommendation (Oramas et al. 2017). One advantage of the explicit semantics of Linked Data is that they can also be used to optimize specific measures like diversity (Musto et al. 2017a). Furthermore, Linked Data can serve as a basis to generate explanations and to thereby increase recommendation transparency (Musto et al. 2019). Overall, data from the LOD cloud were successfully applied for recommendations in several domains, and various opportunities exist to connect LOD information with other types of side information, as shown in Oramas et al. (2017) for music recommendation.
User-generated content (UGC) With the emergence of the participatory web (Web 2.0), various types of UGC became available, such as product reviews, user tags and forum discussions. Most of the early works that tried to leverage this information in the recommendation context focused on user-provided tags, which were used in a variety of ways, e.g., to enhance user and item profiles, or to explain recommendations to users (Jäschke et al. 2007; Vig et al. 2009). Footnote 1 In another stream of works, researchers focused on user reviews and tried to extract various types of information from them, including semantics or user opinions and sentiments, that can be used in the recommendation process. Like for the tag-based approaches, recommendation methods based on UGC not only leverage this side information to improve recommendation quality, but also as a means to explain the recommendations to users. An in-depth review of such approaches can be found in Chen et al. (2015).
Visual and multimedia features As CBF-methods were traditionally text-based, non-textual objects were commonly represented by metadata descriptions. Advances in image and video analysis however made it possible to represent multimedia object by features that were extracted from the objects themselves. Many of these features are in fact difficult to represent in text, e.g., textures or stylistic aspects. McAuley et al. (2015), for example, trained a Convolutional Neural Network on product images to learn how different visual feature dimensions relate to each other across different types of products. The resulting “style space” can then be used to recommend, e.g., trousers that go with a particular pair of shoes. Another example in that context is the work by Elahi et al. (2017), who extract low-level features such as colors, textures, motion and lighting from movies to build a hybrid recommendation system. In a related study Deldjoo et al. (2018), the authors found that these stylistic properties can lead to better recommendations than semantic (object) information that is extracted from the movies through a pre-trained neural network. For the future, we expect that visual and multimedia features will be used for recommendation in many other domains and scenarios where such data is available, such as advertisement, e-commerce and games.
Heterogeneous information networks Finally, a number of recent works aim to connect various types of side information in parallel. In such approaches, the available data is represented as a Heterogeneous Information Network (HIN), where the semantic relationships between objects are represented through different types of relations between the network nodes. Early work on using social networks for recommendation focused on modelling trust (Golbeck 2006) between connected users. An example of a more recent work is that by Kleinerman et al. (2018) who leveraged such a network to generate explanations in the context of reciprocal recommendation scenarios like online dating. Generally, with the increasing number of knowledge sources that become available, HIN-based approaches will continue to gain importance, e.g., to create multi-dimensional user profiles (Jannach et al. 2017).
Meta-path based approaches From an algorithmic perspective, the availability of typed links between different types of objects in HINs inspired the development of meta-path based algorithms, where a meta-path connects two objects through a sequence of labeled relations between object types (Sun et al. 2011). Shi et al. (2015) for example demonstrated that meta-path-based algorithms are useful for HINs in many recommendation domains, e.g. for movie recommendation with types such as users, movies, actors, and directors or between customers, products, businesses and locations. In another approach, Yu et al. (2014) exploited meta-path-based latent features to represent the connectivity between users and items along different types of paths. From the implicit feedback on items, a user-specific weighting of the heterogeneous relationships between the items and other entities is learned to offer personalized recommendations. As HINs become richer and more ubiquitous, we expect that meta-path based approaches will receive more attention in the future.
New metadata encodings While TF-IDF or latent space representations are still common to encode textual item descriptions in CBF approaches, embeddings emerged in recent years as a promising new encoding method that can be used to identify latent connections between the terms in a document. Meta-Prod2Vec (Vasile et al. 2016), for instance, is an approach that computes low-dimensional embeddings of item metadata for sequence-based item recommendation in a hybrid model that uses music playlists and listening data as interactions for CF. Kula (2015), on the other hand, combined user and item metadata to train embeddings for generating recommendations in the fashion domain. In their application scenarios, the embeddings were specifically used to enable transfer learning to improve content-based recommendations for cold-start items and users. Given the flexibility of embeddings, we expect to see more complex models that combine metadata and textual and non-textual content features.
Deep learning Deep Learning (DL) approaches offer a flexible framework to discover existing structures in item and user data, including external knowledge resources (Musto et al. 2018) and non-textual features (Deldjoo et al. 2018), to learn better feature representations. Another advantage of deep neural networks is their ability to model temporal and sequential aspects, which makes them suitable for session-based and sequence-aware recommendation tasks in domains such as e-commerce (Hidasi et al. 2016) and news (Song et al. 2016). In addition, they can be trained to generate rich explanations from user reviews (Lu et al. 2018). Zhang et al. (2017) recently demonstrated the potential of joint representation learning based on the increasing number of heterogeneous sources of textual and multimedia content features, external knowledge resources as well as user context and interaction data. Another recent research direction is to improve the interpretability of DL models for transparent and explainable recommendations (Seo et al. 2017b).
We foresee a number of research directions for exploring the role of content, metadata and side information in recommender systems.
Transparent recommendations In recent years and with the use of increasingly complex machine learning models, we can observe a rising interest in the topic of Explainable AI. This is in particular the case in scenarios of complex human decision-making, where accountability and explainability are important properties, such as health. Explanations have been explored for several years in the context of recommender systems (Nunes and Jannach 2017; Tintarev and Masthoff 2008), and different types of side information have been used in existing explanation approaches. While existing approaches often use side information to highlight features of the recommended items (Gedikli et al. 2014; Vig et al. 2009), one area of future work could be to use side information to explain the internal mechanisms that guide otherwise black-box-like algorithms. This could, for instance, be done by “labeling” internal components of the derived models (e.g., a specific layer of a neural network or a latent factor of a factorized matrix), or by using descriptive features to explain the overall behavior of a recommendation algorithm. In this context, one open research question relates to the choice and possible combination of the features that are used in the explanation process, such as descriptive features (e.g., item properties and curated metadata), user-generated content (e.g., textual reviews and tags), collaborative information, and other sources.
New algorithms and tasks Content-based recommendation has, because of its reliance on complex textual content, traditionally been inspired by the developments in the fields of computational linguistics and natural language processing (NLP). For example, (word) embeddings are beginning to see widespread application in recommendation after its successful application in many NLP tasks. We expect this transfer of methods and techniques to continue in the future. For instance, contextual embeddings have recently been shown to outperform the state-of-the-art on certain NLP tasks (Seo et al. 2017a), and they could show promise for content-based recommendation algorithms as well. Besides such algorithmic improvements, another fruitful research direction would be to investigate the role of content information in alternative types of recommendation tasks (Jannach and Adomavicius 2016) besides standard item ranking or ratings prediction. For instance, generating recommendations for related or similar items (Yao and Harper 2018), or recommending composites or sequences of items.
New types of content Some domains are rich in non-textual content, which is currently still difficult to utilize effectively, such as multimedia content. So far, multimedia recommendation mostly relies on implicit and explicit user feedback, but we expect that the rapid developments in DL algorithms will enable more structured and effective ways of extracting and using semantic and stylistic features in the future, as done in Messina et al. (2018) in this issue. Open research questions here include how and which features can be extracted from multimedia content, and how they should be integrated with user-generated content and user preference data to provide the most relevant recommendations. A more thorough understanding of cross-domain recommendation—how content from one domain can help recommendation in another—would also be important here; see also Hernández-Rubio et al. (2018) (this issue).
The papers in this issue continue many of the recent trends that were discussed above. They use various types of side information including User-Generated Content and Linked Open Data as well as features that are automatically derived from the multimedia objects themselves. From an algorithmic perspective, these papers often rely on deep learning approaches for feature extraction or recommendation. Various application domains are considered as well, including traditional ones like music or news recommendation, as well as novel ones like artwork recommendation.
The paper Content-Based Artwork Recommendation: Integrating Painting Metadata with Neural and Manually-Engineered Visual Feature (Messina et al. 2018) introduces a novel approach for artwork recommendation. The authors combine a variety of information sources—including item metadata as well as low-level visual features that are extracted through a deep neural network—and show the advantage of their combined approach based on an experiment with real-world data provided by an online artwork store.
The paper Movie Genome: Alleviating New Item Cold Start in Movie Recommendation (Deldjoo et al. 2019) adopts a similar ideas and combines a variety of features, both meta-data as well low-level visual and audio features, in a recommender system for movies. They furthermore combine their content-based model with collaborative information in a hybrid approach. Both an offline analysis as well as a preliminary user study confirm the usefulness of their model for new item cold start situations.
The work Affective recommender systems in online news industry: how emotions influence reading choices (Mizgajski and Morzy 2018) studies the role of emotions in the recommendation process. Based on a set of affective item features, a multi-dimensional model of emotions for news item recommendation is proposed. Experiments revealed the potential of considering emotional reactions and in their case, the enhanced recommendation method led to higher click-through-rates.
The paper A comparative analysis of recommender systems based on item aspect opinions extracted from user reviews (Hernández-Rubio et al. 2018) focuses on user-generated content. It provides an in-depth survey of recommender systems that exploit information extracted from user reviews and aims to identify the best techniques for each step when recommending based on user opinions. Furthermore, the paper outlines a number of future directions for review-based recommenders and contributes a number different helpful resources for researchers, including domain-specific aspect vocabularies and lexicons.
Data-related aspects and the use of Linked Open Data is the focus of the paper Addressing the user cold start with cross-domain collaborative filtering: Exploiting item metadata in matrix factorization (Fernández-Tobías et al. 2019). In their work, the authors specifically investigate the use of LOD-based metadata to improve matrix factorization models for cross-domain collaborative filtering. Their experiments emphasize the potential value of considering such knowledge sources, not only to make more accurate recommendations particularly in cold-start situations, but also to balance the trade-off between accuracy and diversity.
The paper Connectionist Recommendation in the Wild: On the utility, scrutability, and scalability of neural networks for personalized course guidance (Pardos et al. 2019) is an example of a work that relies on embeddings to encode metadata. The authors propose Course2Vec, an adaptation of Word2Vec, to build a vector space representation of university courses. Their ultimate goal is to recommend a sequence of courses to enroll to students. Their experiments not only showed the effectiveness of the approach but also demonstrated that the recommendations are “scrutable”, which can be a main prerequisite in real-world applications.
Finally, the paper Feature-combination hybrid recommender systems for automated music playlist continuation (Vall et al. 2019) contributes to the area of music recommendation. The authors introduce two feature-combination hybrid recommender systems that combine collaborative information from curated music playlists with song features. Their experiments show that the proposed methodology leads to competitive results when compared to CF-based systems, and that it can outperform CF methods when training data is scarce. The work therefore provides additional evidence of the value of content information in cold-start situations.